Link to the paper: IEEE
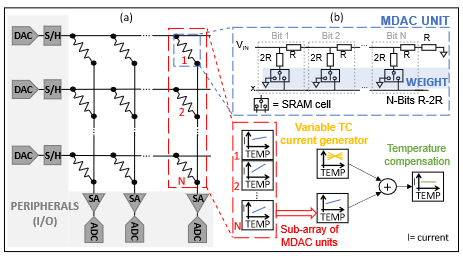
In a nutshell: A simple process and temperature compensation circuitry to be added to resistive-based analog In-Memory Computing (IMC) arrays. This avoids degrading the accuracy of the array (and by extension the AI task that it computes) because of process and temperature non-idealities.
Why? Analog and mixed-signal IMC circuits are becoming popular to build hardware-efficient accelerators for AI computation. Yet, the sensitivity of these circuits to process and temperature variations is typically overlooked. Still, it has been shown that these variations create inaccuracies and degrade the performance of the AI task, which is an issue...
How? We added a simple yet effective compensation circuitry, that can generate current with variable temperature coefficient to compensate for the variations at the bottom of a IMC column. The compensation circuitry has been taped out and measured, showing that non-idealites due to process and temperature variations can be well compensated. Now needs to be tested on bigger arrays!
Some personal context/comments: My team, along with Aalto's Electronic Circuit Design unit, has been working on IMC accelerators for a few years now (hopefully we get more extensive results to show soon). One thing that we realized is that in terms of mixed-signal accelerators, there is a critical need to evaluate the robustness/reliability of the analog circuitry itself (not only eventual emerging memory technologies we use to build the chip). So we started to look into this, in particular going back to simple compensation techniques and see how effective they can be. This is the first paper we get to publish on this topic!
